Paolo's Blog Random thoughts of a Junior Computer Scientist
Introduction to Reinforcement Learning

What does it mean to learn something? What is learning?
Intuitively learning for us means interacting with an external environment, do something, see what happens and act consequently, see what happens and act consequently again, and so on …
So the question of the researchers was: ‘Why don’t we apply this process also to the machines? Nature gives us everything that we need, so why don’t we just trying to copy what nature did?’ Well, this is how the area of machine learning called reinforcement learning came about.
Reinforcement learning takes a completely different approach from the other paradigms of machine learning: supervised and unsupervised learning. Here’s we don’t want to find a model that generalized well the data, given a training set of labeled examples provided by a knowledgeable external supervisor. Or we don’t even want to find the hidden underline structure in collections of unlabeled data.
Reinforcement learning problems involve learning what to do - how to map situations to actions - so as maximize a numerical reward signal. In an essential way, they are closed-loop problems because the learning system’s actions influence their later inputs. Moreover, the learner is not told which actions to take, as in many forms of machine learning, but instead must discover which actions yield the most reward by trying them out. In the most interesting and challenging cases, actions may affect not only the immediate reward but also the next situation and, through that, all subsequent rewards.
In simpler words, our agent is interacting with an environment and it trying to behave in a way that will maximize the rewards that he gets from the environment.
At the beginning of his life, the agent has to operate despite significant uncertainty about the environment it faces. It’s only through experience, hence through trials and errors, that the agent will learn how to choose the right action that will maximize the rewards.
Sound familiar right? Isn’t it the way we learn?
Build blocks of RL
In order to make the agent learn something, we have to put him in an environment. In Reinforcement learning we can have two types of environment:
-
Fully Observable environments: in these types of environments the agent directly observes the environment’s states, he gets to see everything. So here the observations that we see is the same as the agent state which is the same as the environment state ( \( O_t = S_t^a = S_t^e \)). We can formalize the fully observable environments as a Markov decision process (MDP).
-
Partially Observable environments: in these types of environments the agent indirectly observes the environment, so it doesn’t get to everything of the environment. And now the agent state is distinct from the environment state because we don’t know the environment state. And this type of environment needs a different formalism which is the partially observable Markov decision process (POMDP). And now our job is to build the agent state \( S_t^a \). But how do we do that? Well, there are a lot of ways we can do it:
- The naive approach is just to remember everything, so all the observations, states and actions, rewards we’ve seen so far. So \( S_t^a = H_t \).
- The other approach is based on probability , so we build a vector of beliefs for every state \( S_t^a = (\mathbb{P}[S_t^e = s^1], … , \mathbb{P}[S_t^e = s^n]) \)
- Another choice is to use a recurrent neural network, which is a neural network with an internal state (memory) \( S_t^a = \sigma(S_{t-1}^a W_s + O_t W_o) \)
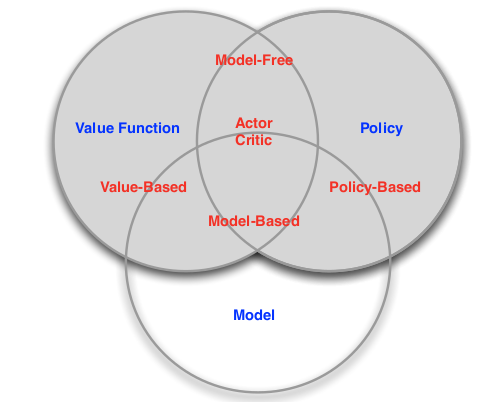
Beyond the agent and the environment, the others build blocks of a reinforcement learning system are: a policy, a reward signal, a value function, and, optionally, a model of the environment.
A policy defines the learning agent’s way of behaving at a given time. Roughly speaking, a policy is a mapping from perceived states of the environment to actions to be taken when in those states. The policy is the core of a reinforcement learning agent in the sense that it alone is sufficient to determine behavior.
Mathematically we can describe a policy as follow:
- as a function \(a = \pi(s)\) that maps a state \( s \) into action \( a \) if we need a deterministic policy
- or as a probability distribution \( \pi(a|s) = \mathbb{P}[A_t = a | S_t = s] \) that gives us the conditional probability of choosing action \( a \) given the state \( s \), if we need a Stochastic policy
A reward signal defines the goal of a reinforcement learning problem. On each time step, the environment sends to the agent a reward, which in most cases is a number ( an integer or a floating-point number). The agent’s goal is to maximize the total reward it receives over the long run. So the reward tells the agent what are the good and the bad events. In a biological system, we might think of rewards as analogous to the experience of immediate pleasure and pain. The reward sent to the agent at any time depends on the agent’s current action and the current state of the agent’s environment.
Obviously, the reward signal is the main signal that is being watched for altering the policy. If an action selected by the policy is followed by a low reward, then the policy may be changed to select an action that will get a higher reward in the future.
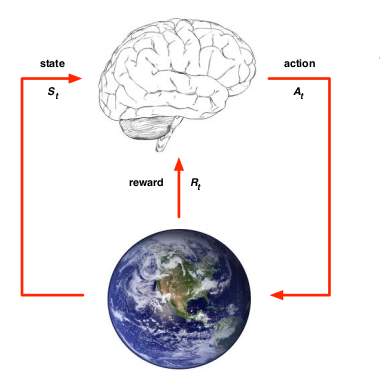
Whereas the reward signal indicates what is good in an immediate sense, a value function specifies what is good in the long run. Roughly speaking, the value of a state is the total amount of reward an agent can expect to accumulate over the future, starting from that state. Whereas rewards determine the immediate, intrinsic desirability of the environmental states, values indicate the long-term desirability of states after taking into account the states that are likely to follow, and the rewards available in those states.
A trivial example might be an agent that represents a university student, whose instead of following the class, he distracts himself with the phone. Of course, picking up the phone will give an immediate small reward to the student, but over the long run if he keeps going on distracting with the phone on Facebook he won’t pass the exams, which will give him a better reward overall!
But how we are going to estimate those values? If the rewards are basically given directly by the environment, the values must be estimated and re-estimated from the sequences of observations an agent makes over its entire lifetime. In fact, the most important component of almost all reinforcement learning algorithms we consider is a method for efficient values estimation.
Mathematically speking a value function of state \( s \) under policy \( \pi \) is:
\[v_{\pi}(s) = \mathbb[{E}_{\pi}[R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... | S_t = s]\]Where \( 0 \le \gamma \le 1 \) is called the discount factor and basically is a hyperparameter that controls how much we care about future rewards.
The fourth and final element of some reinforcement learning systems is a model of the environment. This is something that mimics the behavior of the environment. For example, given a state and action, the model might predict the resultant next state and next reward. Models are used for planning, by which we mean any way of deciding on a course of action by considering possible future situations before they are actually experienced. Methods for solving reinforcement learning problems that use model and planning are called model-based methods, as opposed to simpler model-free methods that are explicitly trail-and-errors learners – viewed as almost the opposite of planning.
Mathematically we break down the model into two models:
- A state transition model, that tell us the probability of begin in the next state given the previous state and the action:
- A reward model that tells us the expected reward given the previous state and action:
Observations: In Reinforcement learning, we are not seeking optimization we seek optimality. Trying to maximize a quantity does not mean that that quantity is ever maximized. The point is that a reinforcement learning agent is always trying to increase the amount of reward it receives. Many factors can prevent it from achieving the maximum, even if one exists.
Categorizing RL agents
After having introduced the building block of an RL system, let’s see what types of agents we can have:
-
Value Based agent: a value based agent doesn’t have any policy because it uses directly the value function of the states, that tell us how good is to stay in that state
-
Policy Based agent: instead of using the value function it works directly with a policy, without ever explicitly store the value function.
-
Actor Critic agent: combines the previous type of agents and tries to get the best of both of them. This kind of agent stores both the policy and the values.
By combining these things together we obtain the agent taxonomy:
Probelms within Reinforcement Learning
Reinforcement Learning vs Planning
In the science of making an optimal decision, there are two fundamental problems which have different setup and different way of being solved.
First of all, there is a reinforcement learning problem, where the environment is unknown but the agent isn’t told how the environment works. And the way the agent is going to get to know the environment is with interaction, and through interaction with the environment it’s figuring out a better policy that’s gonna maximize reward and get the most possible future rewards.
And there’s a second problem setup which is called Planning. Planning is different from reinforcement learning, in the planning problem the environment is known, we tell the agent “all the rules of the game”. And instead of interaction with the environment the agent performs internal computation with this model, for example, he might do lookahead planning. It does not require to collect true experience from the real environment, but some planning methods are based on simulated experience from the known environment. So after figuring out how to behave in this environment the agent improves its policy. Planing is often performed “offline”, that is, you “plan” before executing. While you’re executing the “plan”, you often do not change it.
And of course one way of doing reinforcement learning is to learn how the environment works, build a model of the environment and then do planning. So these two problems they are linked together but they have a very different setups.
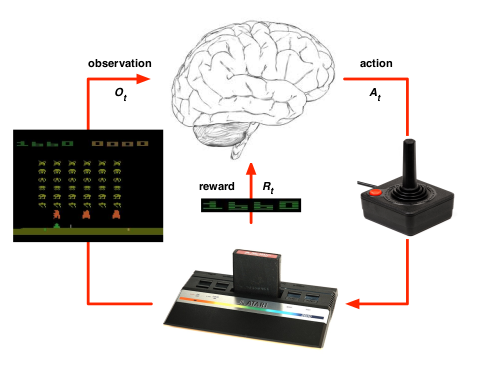
For example, let’s say that we are building an agent that is trying to learn the atari games.
| Reinforcement Learning | Planning |
|---|---|
 |
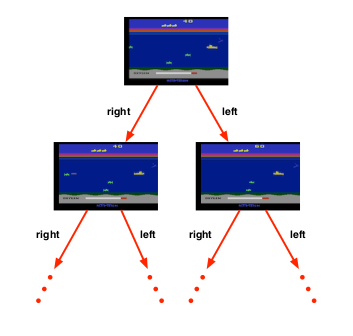 |
| In the Reinforcement Learning setting the agent doesn’t know the rules of the game, so the only thing that he can do is figuring out, through trial and error, the rules are and how the game works. | In the planning problem, we have complete knowledge of how the emulator works, what are the rules of the game. So by having this information, we can do a lookahead search, a tree search, or any other planning method to find the optimal policy. |
Eploitation vs Exploration
The balance of exploration and exploitation is another non-trivial problem. We can think about reinforcement learning as a sort of trial and error learning, we don’t know how the environment looks like, we have to figure out through trial and error, we have to find out which part of the space are good and which are bad. The things are that while we do it we might losing rewards along the way, so the goal is that we want to figure out a good policy, we want to figure out the best part of the space. So the agent should discover a good policy from its experiences of the environment, without losing too much reward along the way and also trying to give a shoot to explore other parts of the space.
Exploration means choosing to give up some rewards that you know about, to find out more about the environment.
While exploitation means exploiting the information you’ve already found to maximize the reward.
The field of Reinforcement learning had a significant boost in the lastest years. You might hear of the Google’d Deepmind team that beats the Go world champion using RL. Another example is the MuZero Paper where still the Deepmind team showed how the build an RL algorithm achieves superhuman performance in games such as Atari, Go, Chess, and Shogi. This AI field is so exciting! Can’t wait to see what’s gonna happen in the next five years!
Further Resources
- David Silver RL Course on Youtube
- Sildes of the RL Course by David Silver
- Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction
- MuZero Paper